


{kind=link}
Nvidia / Benj Edwards
On Monday, Nvidia unveiled the Blackwell B200 tensor core chip—the company’s most powerful single-chip GPU, with 208 billion transistors—which Nvidia claims can reduce AI inference operating costs (such as running ChatGPT) and energy consumption by up to 25 times compared to the H100. The company also unveiled the GB200, a “superchip” that combines two B200 chips and a Grace CPU for even more performance.
The news came as part of Nvidia’s annual GTC conference, which is taking place this week at the San Jose Convention Center. Nvidia CEO Jensen Huang delivered the keynote Monday afternoon. “We need bigger GPUs,” Huang said during his keynote. The Blackwell platform will allow the training of trillion-parameter AI models that will make today’s generative AI models look rudimentary in comparison, he said. For reference, OpenAI’s GPT-3, launched in 2020, included 175 billion parameters. Parameter count is a rough indicator of AI model complexity.
Nvidia named the Blackwell architecture after David Harold Blackwell, a mathematician who specialized in game theory and statistics and was the first Black scholar inducted into the National Academy of Sciences. The platform introduces six technologies for accelerated computing, including a second-generation Transformer Engine, fifth-generation NVLink, RAS Engine, secure AI capabilities, and a decompression engine for accelerated database queries.

Several major organizations, such as Amazon Web Services, Dell Technologies, Google, Meta, Microsoft, OpenAI, Oracle, Tesla, and xAI, are expected to adopt the Blackwell platform, and Nvidia’s press release is replete with canned quotes from tech CEOs (key Nvidia customers) like Mark Zuckerberg and Sam Altman praising the platform.
GPUs, once only designed for gaming acceleration, are especially well suited for AI tasks because their massively parallel architecture accelerates the immense number of matrix multiplication tasks necessary to run today’s neural networks. With the dawn of new deep learning architectures in the 2010s, Nvidia found itself in an ideal position to capitalize on the AI revolution and began designing specialized GPUs just for the task of accelerating AI models.
Nvidia’s data center focus has made the company wildly rich and valuable, and these new chips continue the trend. Nvidia’s gaming GPU revenue ($2.9 billion in the last quarter) is dwarfed in comparison to data center revenue (at $18.4 billion), and that shows no signs of stopping.
A beast within a beast

The aforementioned Grace Blackwell GB200 chip arrives as a key part of the new NVIDIA GB200 NVL72, a multi-node, liquid-cooled data center computer system designed specifically for AI training and inference tasks. It combines 36 GB200s (that’s 72 B200 GPUs and 36 Grace CPUs total), interconnected by fifth-generation NVLink, which links chips together to multiply performance.
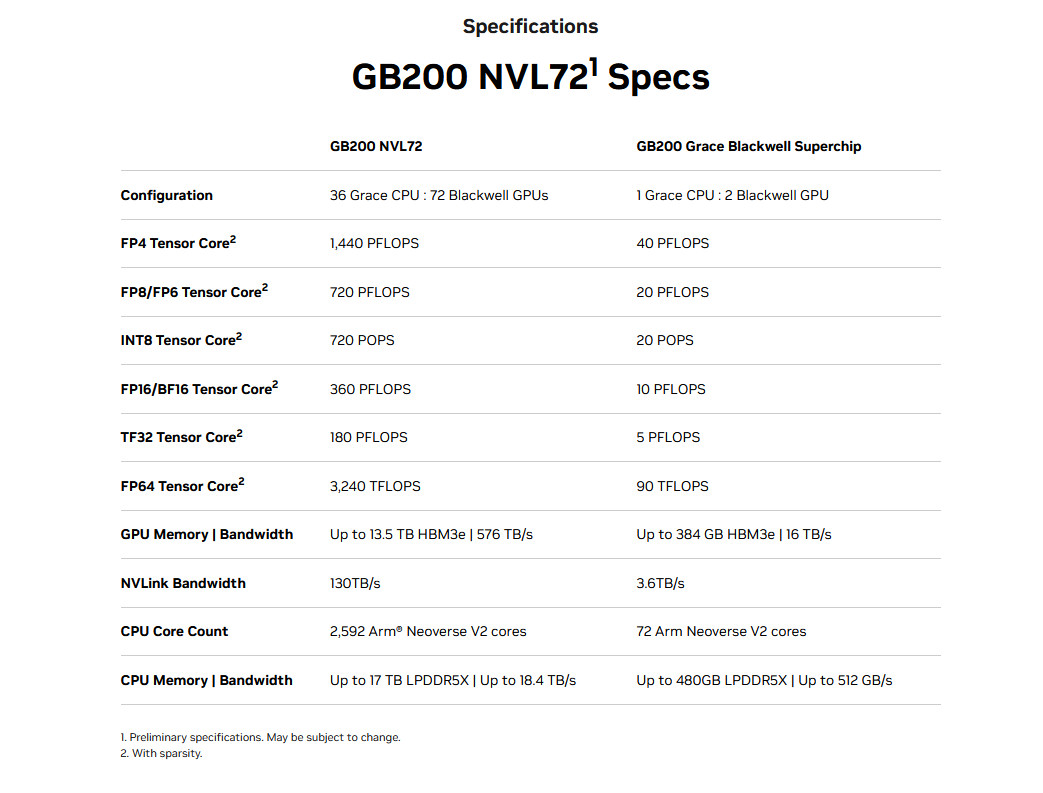
“The GB200 NVL72 provides up to a 30x performance increase compared to the same number of NVIDIA H100 Tensor Core GPUs for LLM inference workloads and reduces cost and energy consumption by up to 25x,” Nvidia said.
That kind of speed-up could potentially save money and time while running today’s AI models, but it will also allow for more complex AI models to be built. Generative AI models—like the kind that power Google Gemini and AI image generators—are famously computationally hungry. Shortages of compute power have widely been cited as holding back progress and research in the AI field, and the search for more compute has led to figures like OpenAI CEO Sam Altman trying to broker deals to create new chip foundries.
While Nvidia’s claims about the Blackwell platform’s capabilities are significant, it’s worth noting that its real-world performance and adoption of the technology remain to be seen as organizations begin to implement and utilize the platform themselves. Competitors like Intel and AMD are also looking to grab a piece of Nvidia’s AI pie.
Nvidia says that Blackwell-based products will be available from various partners starting later this year.